From 82% to 99.8%: How hybrid search improved our legal agents

We've been poking at our retrieval pipeline recently and taking a look at how we surface the right document from a growing corpus of legislation, case law, tribunal decisions, housing guidance, etc. When the agent can reliably find the exact precedent it needs, the quality of everything downstream improves dramatically, be it legal analysis, case building, or just the general agent-user interactions that drive our platform.
We got curious about how much room for improvement there actually was, and whether a few targeted changes to the retrieval step could meaningfully shift the quality of everything the agent produces. We wanted our agent to know which tribunal decision supports your case and why, instead of giving you a confident-sounding summary of law it never read. In our mind that's part of what separates a purpose-built legal agent from ChatGPT and it's the kind of problem that sounds solved until you measure it.
The baseline
We started by narrowing the problem down to 550 of our case law documents as a testbed. They're the hardest to search well, in that they're dense, structurally inconsistent, and cover overlapping areas of law in wildly different levels of detail.
The obvious first approach was to embed each document as a single vector and search by cosine similarity: straightforward, well-documented, works out of the box, don't-reinvent-the-wheel type of programming. To measure how well it worked, we ran self-retrieval tests; we'd take each document's description, use it as a query, and check whether the system can find the original document in the top 10 results. It's a decent baseline because if the system can't find a document when given its own description, it's certainly going to struggle with fuzzier real-world queries. But, importantly, these queries are typically generated by an agent as part of an autonomous agentic searching system.
Hit rate came back at 82.4%. Not great. In a legal context missing 1 in 5 relevant documents isn't great when the whole point is that you surface the right case. A user asking about a specific tribunal decision on rent repayment orders shouldn't be getting results about an unrelated disrepair claim just because both documents mention "landlord obligations."
Why whole-document embeddings fall short
We noticed something odd when the system started returning the same handful of case law documents for completely different queries. Long tribunal decisions that covered distinct areas of law were being treated as interchangeable. The embeddings were getting diluted; a 768-dimensional vector has to represent the entire semantic content of a document, and that poses problems when the document is an 85,000-token tribunal decision covering procedural history, multiple legal arguments, statutory interpretation, and a final ruling. The embedding ends up as a centroid of all those topics that doesn't strongly represent any one of them.
If that's a bit abstract, think of it geometrically. Each topic in a document pulls the embedding vector in a different direction. A short, focused document, say, a single statutory instrument defining a specific obligation, gets an embedding that sits cleanly in one region of the vector space. But a long tribunal decision that touches housing disrepair, procedural fairness, costs, and three different statutes ends up as an average of all those directions; close-ish to lots of things but not particularly close to any of them.
Here's what that looks like when you project a randomly-chosen subset of our corpus embeddings down to two dimensions (colour = document length, shape = document category):
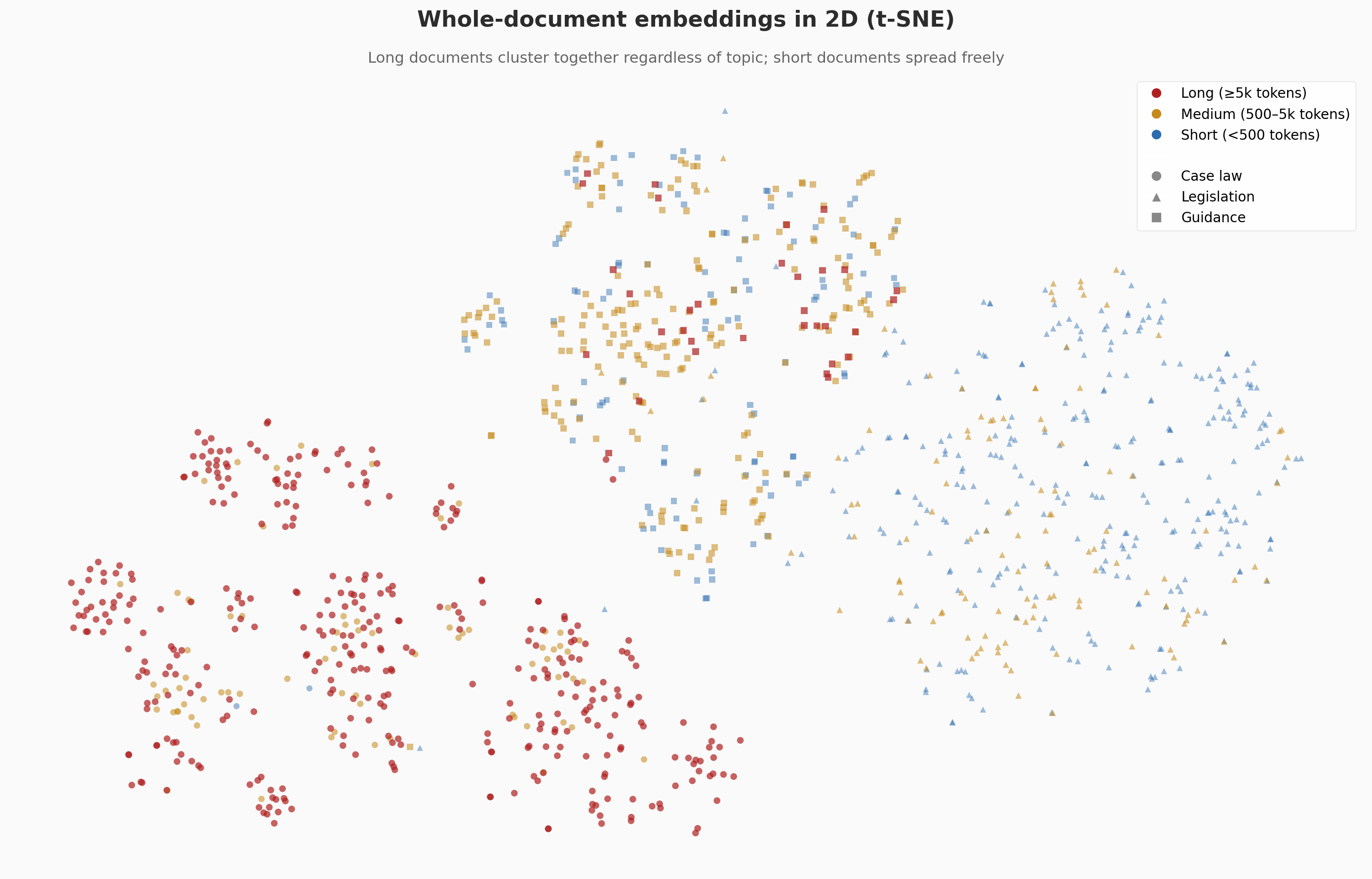
If these long documents were being embedded by topic, you'd expect to see multiple distinct clusters of red dots spread across the space, i.e. one cluster for disrepair cases, another for eviction cases, another for rent repayment, and so on. Instead, they're concentrated in a single region and the embeddings are grouping by the fact that the document is a long, multi-topic legal document. If you look closely at the shapes, you'll notice that the few long documents (red) that do sit elsewhere are triangles and squares (legislation and guidance), which tend to be topically focused even when they're long. The case law circles don't get that luxury, as each decision spans multiple legal topics, and the embedding has no choice but to average them all into the same part of the space.
Chunking
Chunking is a pretty standard first step here, which involves splitting the documents into smaller segments so each embedding represents a focused idea rather than an entire document. We went with ~250-token segments with sentence and paragraph-aware splitting so chunks don't break mid-thought. The size wasn't arbitrary, guided by Bhat et al.'s work on chunk size optimisation in dense retrieval. Our corpus sits in a middle ground between fact-based and contextual content, and ~250 tokens hit the sweet spot. Too small and you lose context (a sentence about "the landlord's obligation" means nothing without knowing which obligation). Too large and you're back to the centroid problem.
Each chunk gets its own embedding, and at search time we match against the most relevant chunk then trace back to the parent document. LangChain enthusiasts might recognise this as the parent-document retrieval pattern that keeps the precision of small embeddings without losing the context of the full page, and we were definitely inspired by the example they set, though we had to adapt the implementation quite a bit to fit our corpus and search infrastructure. The vector now represents one coherent idea rather than a centroid of everything, which helped, but the cases it missed pointed to something different. Semantic matching was working well for queries phrased in natural language but the failures were a different kind of problem entirely.
Where embeddings stop helping
Embeddings operate in continuous vector space, meaning that they're excellent at semantic proximity; "quiet enjoyment" matches "peaceful occupation of premises," "retaliatory eviction" matches "revenge eviction by landlord", but they have no mechanism for exact symbolic matching. Legal text is full of identifiers that exist outside semantic space: "section 21(1)(b)", "Housing Act 2004", case citation numbers. These are arbitrary symbols, and there is no semantic relationship between "section 21" and "section 20" that an embedding model can learn; they're just labels that happen to be numerically adjacent.
Two statute references are equidistant from each other in embedding space regardless of whether they're related. And yet these identifiers are often the most important signal in a legal query. When a housing advisor searches for "section 21 validity requirements," the "section 21" part is doing most of the work, and it's exactly the part that embeddings handle worst. When we looked at the failures from the vector-only run, it turned out that almost every miss was a query anchored to a specific legal identifier, like a statute reference, a case citation, or a specific procedural rule. The semantic content of the query was fine but the embedding just couldn't distinguish between documents that discussed similar themes whilst referencing different legislation.
Adding the keyword signal
We didn't have to look far. BM25-style keyword ranking has been around for decades, and hybrid search is hardly a novel idea in RAG development. But the fit for our problem was almost too neat to ignore, considering we had a retrieval system that was great at semantic matching but structurally blind to exact identifiers (and keyword search is literally just exact matching with term weighting). So we added a keyword signal that closely emulates BM25 scoring (we won't bore you with exactly how; trade secrets and all) and used Reciprocal Rank Fusion to combine the two rankings. RRF is nice because it sidesteps the normalisation problem entirely. Cosine similarity scores and BM25 relevance scores live on completely different scales so you can't meaningfully compare 0.82 cosine similarity with 3.7 BM25 relevance; and RRF doesn't try to.
RRF instead converts each ranking to a positional score: 1/(k + rank), where k is a constant (and the standard value of 60 worked well in our case). A document ranked first by vector search gets a score of 1/61; ranked third gets 1/63. The same calculation happens independently for the keyword ranking, and the two scores are simply summed. Documents that appear in both rankings get a natural boost, and documents that only one system found still surface purely off rank arithmetic.
The results
We ran the same 550 self-retrieval queries against the hybrid system.
99.8%: one miss out of 550.

The jump from 82.4% to 99.8% came almost entirely from the keyword signal catching the exact queries that vector search was structurally unable to handle, which in hindsight makes complete sense, but we weren't expecting for it to be this fitting. The single miss remaining in the hybrid search stress test is an edge case (specifically a particularly unusual tribunal decision whose description doesn't share enough distinctive terms with its content for either signal to surface it confidently). At a certain point, one miss in 550 is about as good as self-retrieval testing can measure.
Performance-wise, the hybrid search runs at ~13ms P50 for the query itself, and even factoring in embedding latency the full round-trip sits at ~88ms P50, which was all achieved running on the same Postgres instance we already had.
What's next
Rolling this out across the full corpus once we're happy with the evaluation. Self-retrieval numbers from staging already show pass@k sitting at 99.9% across the full 31,000-document corpus, with the only miss being the same edge case from the case law testbed.
That said, self-retrieval is a controlled test and the queries are derived from the documents themselves, so there's an inherent advantage baked in. We've since run a broader evaluation pass with agent-generated queries that the system hasn't seen before, and the results are holding up very well. We're continuing to build out the suite and test it against cross-register queries where the expected result might be a piece of legislation rather than a case, multi-hop queries that require chaining multiple documents together, and adversarial queries designed to trip up the ranking.
There is lots still to learn. Early days, but legal support that's grounded in real authority rather than guesswork is the kind of thing we're working on at Remedy.